

صفر تا صد آموزش دادهکاوی با پایتون؛ در چند مرحله ساده برای تازهکارها

در سال 2025 داده به «طلای دیجیتال» معروف است، چون میتواند بینشهایی (Insight) فوقالعاده و دیدگاههایی دقیق در اختیار کسبوکارها قرار دهد. با تحلیل درست دادهها، دیگر تصمیمگیری بر پایه حدس و گمان نیست، بلکه بر پایه شواهد آماری انجام میشود. برای رسیدن به چنین نتایجی، پایتون یکی از بهترین ابزارها در حوزه دادهکاوی به شمار میرود. در ادامه گامبهگام با آموزش دادهکاوی با پایتون آشنا میشویم تا ببینیم چگونه میتوان از دادهها به دانش واقعی رسید. در ادامه مسیر یادگیری دادهکاوی، اگر تازه با برنامهنویسی آشنا شدهاید، میتوانید با آموزش پایتون مقدماتی شروع کنید و سپس با دوره پایتون متوسط مهارتهای خود را برای کار با دادهها و پیادهسازی الگوریتمهای دادهکاوی تقویت کنید.
تخفیفهای شگفتانگیز جشنواره آکادمی چابک
تخفیف بگیر و ثبت نام کن!
چرا داده کاوی با پایتون اهمیت دارد؟
دادهکاوی با پایتون اهمیت بالایی دارد، چون این زبان با کتابخانههای قدرتمندش، تحلیل دادههای حجیم را برای متخصصان و پژوهشگران سریعتر میکند.
پایتون کتابخانههایی مانند Pandas، NumPy و Scikit-learn را در اختیار شما میگذارد تا بتوانید از دادههای خام، الگوها و ارتباطهای پنهان را استخراج کنید. وقتی تحلیلگر بتواند از دادهها معنا بیرون بکشد، تصمیمگیری در کسبوکار، پژوهش یا حتی مدیریت منابع، به سطحی کاملاً هوشمندانهتر میرسد.
حالا چگونه این کار انجام میشود؟ در ادامه کامل آموزش دادهایم:
همین حالا ثبتنام کنید!
مرحله اول
داده کاوی با پایتون چیست؟ مفاهیم پایه را درک کنید
برای شروع آموزش دیتا ماینینگ با پایتون بهتر است بدانید اصلا دادهکاوی چیست و در کجاها استفاده میشود.
دادهکاوی با Python فرآیند کشف الگوهای پنهان در دادههاست که از آن در تشخیص تقلب در بانکها، تحلیل شبکههای اجتماعی و بسیاری از صنایع دیگر استفاده میشود. این مفاهیم پایه دادهکاوی را میتوان با کودکان هم به صورت جذاب آموزش داد؛ برای مثال، با دوره اسکرچ جونیور میتوان مفاهیم الگوریتمی ساده و کشف الگوها را به آنها یاد داد.
مرحله دوم
کتابخانههای لازم برای داده کاوی با پایتون را نصب کنید
برای شروع آموزش داده کاوی با پایتون Data Mining with Python باید بدانید که کدام کتابخانههای پایتون برای دادهکاوی ضروری هستند:
| ابزار | توضیح | دستور نصب |
|---|---|---|
| Jupyter Notebook | محیط ساده برای اجرای کد | pip install jupyter |
| Pandas, NumPy | تحلیل داده و محاسبات عددی | pip install pandas numpy |
| Scikit-learn | الگوریتمهای یادگیری ماشین | pip install scikit-learn |
| Seaborn, Matplotlib | تجسم دادهها | pip install seaborn matplotlib |
پیشنهاد: از JupyterLab برای آموزش عملی دادهکاوی با پایتون استفاده کنید تا کد، خروجی و نمودار را یکجا ببینید.
مرحله ۳: دادهها را جمعآوری و سپس آمادهسازی کنید
در این مرحله، باید مواد خام تحلیل خود را بهدست آورید؛ یعنی دادهها!
منابع رایگان زیادی وجود دارند که میتوانید از آنها استفاده کنید، از جمله:
- Kaggle (مجموعهای از دادههای واقعی و چالشبرانگیز)
- UCI Repository (مناسب برای تمرین پروژههای دانشگاهی و شخصی)
- Data.gov (منبع دادههای دولتی و عمومی)
پس از دانلود دادهها، کافی است آنها را با پایتون وارد محیط کاری خود کنید:
import pandas as pd
data = pd.read_csv(‘dataset.csv’)
در این بخش از نقشه راه داده کاوی با پایتون، هدف شما درک دادهها و آمادهسازی آنها برای مراحل بعدی است.

مرحله ۴: دادهها را پیشپردازش کنید
قبل از اجرای مدلها، دادهها باید تمیز شوند. یعنی اقدامات زیر رویشان صورت بگیرد:
- حذف مقادیر گمشده (dropna())
- جایگزینی دادههای ناقص با میانگین (SimpleImputer)
- شناسایی دادههای پرت با Z-Score یا IQR
در این مرحله، علاوه بر پاکسازی دادهها، شناخت اصول آمار توصیفی و احتمالات نیز اهمیت زیادی دارد. اگر بهدنبال درک عمیقتری هستید، پیشنهاد میشود روی آموزش مفاهیم آماری در دادهکاوی و پیادهسازی آن با پایتون تمرکز کنید تا تحلیلهای دقیقتری انجام دهید.
مرحله ۵: تحلیل اکتشافی دادهها (EDA)
پیش از اجرای هر مدل، باید دادهها را بشناسید. تحلیل اکتشافی یا EDA به شما کمک میکند الگوها، روابط و ناهنجاریهای پنهان در داده را کشف کنید.
برای مثال، برای بررسی همبستگی ویژگیها میتوانید از کد زیر استفاده کنید:
import seaborn as sns
sns.heatmap(data.corr(), annot=True)
در این بخش متوجه میشوید که بدون درک پایهای از آمار نمیتوان الگوها را بهدرستی تحلیل کرد. بنابراین دانستن این نکته که چه مفاهیم آماری برای دادهکاوی با پایتون لازم است، میتواند کیفیت تحلیل شما را چند برابر کند. همچنین مطالبی مانند آموزش هک با پایتون و معرفی کامپایلر آنلاین پایتون برای تمرین سریع قرار دارد.
مرحله ۶: اجرای الگوریتمهای دادهکاوی
در این مرحله، وارد دنیای یادگیری ماشین و دادهکاوی با پایتون میشویم؛ جایی که الگوریتمها به ما کمک میکنند از دادهها بینشهای واقعی استخراج کنیم.
در ادامه سه مورد از الگوریتمهای یادگیری ماشین در پایتون را معرفی کردهایم:
الف) رگرسیون (Regression)
برای پیشبینی مقادیر عددی، مانند قیمت مسکن.
from sklearn.linear_model import LinearRegression
model = LinearRegression().fit(X_train, y_train)
ب) خوشهبندی (Clustering)
برای گروهبندی مشتریان یا دادهها با ویژگیهای مشابه:
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3)
ج) طبقهبندی (Classification)
برای تشخیص دستهی دادهها، مثلاً ایمیل اسپم یا عادی.
- این سه روش، بخش اصلی آموزش داده کاوی و یادگیری ماشین با پایتون را تشکیل میدهند.
مرحله ۷: مدلتان را تا میتوانید بهینه کنید
حالا که مدلتان را ساختید، باید عملکردش را بسنجید و بهترش کنید. برای این کار از معیارهایی مثل Accuracy (دقت کلی)، Precision (درصد پیشبینیهای درست مثبت)، Recall (نرخ تشخیص درست موارد واقعی مثبت) و F1-Score (میانگین هماهنگ دو معیار قبلی) استفاده میشود.
برای مثال:
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))
برای افزایش دقت و اطمینان از عملکرد مدل، از اعتبارسنجی متقاطع (Cross Validation) استفاده کنید.

مرحله ۸: نتایجتان را مستند کنید
در هشتمین مرحله، باید نتایج تحلیل و مدلسازیتان را طوری ارائه دهید که دیگران هم بتوانند آن را درک و استفاده کنند. میتوانید نتایج را بهصورت عملی ارائه دهید و همزمان آموزش پایتون برای بازیسازها را تمرین کنید.
چند پیشنهادی که در این زمینه داریم شامل:
- ساخت داشبورد تعاملی با ابزارهایی مثل Plotly Dash
- مستندسازی مراحل در Jupyter Notebook
- ذخیره گزارش نهایی در قالب HTML یا PDF
مرحله ۹: برای تمرین بیشتر، پروژههای واقعی انجام دهید
حالا شاید بپرسید چگونه میتوانم مفاهیم دادهکاوی را در پایتون پیاده کنم؟ پاسخ ساده است: با انجام پروژههای واقعی و کار روی دادههای کاربردی، مفاهیم به تجربه تبدیل میشوند.
- پیشبینی قیمت مسکن (Regression)
- تشخیص اسپم ایمیلها (Classification)
- سگمنتبندی مشتریان فروشگاه (Clustering)
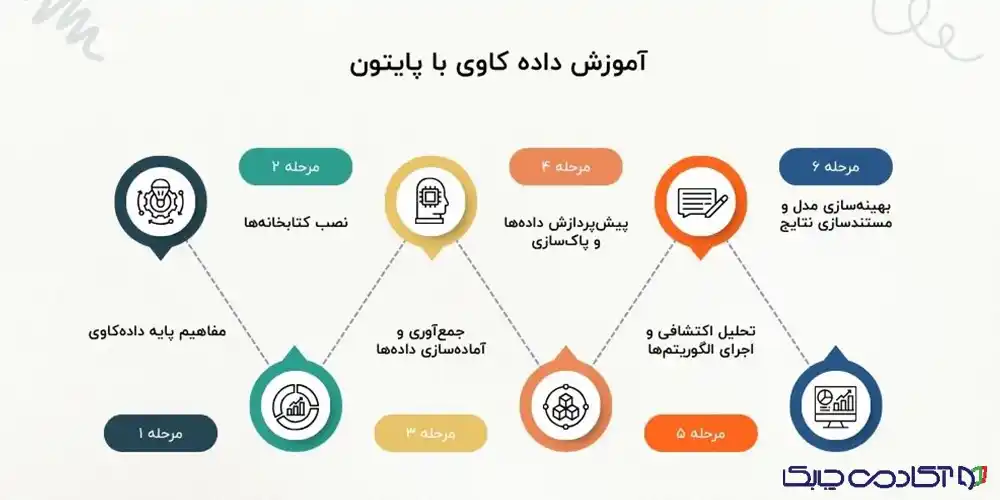
بهترین مسیر یادگیری دادهکاوی با پایتون کدام است؟
برای اموزش داده کاوی با پایتون رایگان به فارسی میتوانید به دورههایی که در آپارت و یوتیوب هست مراجعه کنید؛ ولی پیشنهاد میکنیم برای این که مسیر یادگیری را در کمترین زمان طی کنید، دورههای مقدماتی تا پیشرفتهای مثل دورههای چابک پیدا کنید که عمیق و سریع دادهکاوی را یاد بگیرید.
با آموزش داده کاوی با پایتون در چابک، حرفهای و آماده استخدام شوید!
برای حرکت در مسیر یادگیری و شرکت در دورههای آموزشی آکادمی چابک داده کاوی با پایتون از صفر تا صد، به دو عنصر کلیدی نیاز دارید:
اولی، پشتکار در یادگیری مفاهیم و تمرین مداوم روی پروژههای واقعی؛
دومی، داشتن مسیر آموزشی منظم و پشتیبانی درست از منابع معتبر.
با این دو عنصر و کمی تمرین متمرکز، در مدت کوتاهی میتوانید به یک متخصص دادهکاوی تبدیل شوید. آکادمی چابک همراه شماست تا این مسیر یادگیری را سریعتر و کاربردیتر طی کنید تا در پایان دورهها آماده ورود به بازار کار شوید.
پس همین امروز یادگیری آموزش داده کاوی با پایتون را آغاز کنید و مسیر حرفهای خود را در دنیای دادهها بسازید.
منبع:


دیدگاهتان را بنویسید